That a rather bold and self-inflating misrepresentation, and it's the sort of thing that keeps getting you a 'rep'.
If you don't mind, on WBF forum we show more respect to each other than this. Please make your technical points and let that speak for itself rather than getting personal this way.
What was 'thought' was that a rigorous double-blind comparison that is truly between 'hi rez' vs 'Redbook' formats will yield a negative result...except under extraordinary conditions (like, raising the volume so high that differences in background become audible in conversion that doesn't use dither and noise shaping. Which btw is exactly the sort of difference that Meyer and Moran reported). OF course too, if the comparator tool itself introduces a 'tell', the result could be 'difference'. Ditto if there is distortion at output. You aren't truly comparing 'hi rez to Redbook' in those cases.
You bolded my sentence but then ignored it as you wrote this reply:
"It was thought until now that such ABX tests could not generate positive results. "
"Such tests" means tests created such as ones by Arny where he said I think for some 14 years no one could tell the difference. Here is the intro to the test Arny created which I quoted in the first post in this thread:
Yes. Take the best audio system you can find. Take the best recordings you can find - recordings that sound great and also have significant content > 20 KHz, even > 35 KHz. Switch a 16 KHz brick wall filter in and out of the signal path. Nobody notices nuttin'
See? It says even a resample to 32 Khz is transparent. No qualifications is made as you are putting there. If you go to the link I provided to that conversation, this is what you see:
I did what I said in the previous post. I made recordings of live musicans in an exceedingly quiet and non-reverberent room @24/96 using 1/4" measurement mics that had strong content > 20 KHz, even 30 KHz.
I set up an ABX between the 24/96 files with a 16 KHz brickwall filter, and with full bandpass. I used speakers and amps with strong response > 30 KHz and put the listeners on axis of their supertweeters.
[Amir: where tests sighted or blind]
both
[Amir: And was the person performing the tests had his hearing tested to make sure they could hear above 16 Khz?]
Yes.
The training sequence was files brick walled at lower frequencies such as 9 KHz, and working up in logical steps.
[Amir: And was the person performing the tests had his hearing tested to make sure they could hear above 16 Khz?]
Yes.
So I ran this impossible test where folks that had hearing above 16 Khz could not perceive the difference even down to 32 Khz sample as Arny presented it. He has dithered the file. And I and others managed to hear the difference.
So clearly no one says 'could not', point blank.
Arny has clearly above. And I can find countless others who have said the same.
And here is you in a high-res to CD comparison on AVS:
http://www.avsforum.com/forum/91-audio-theory-setup-chat/797512-196-24-vs-44-16-a.html#post9646092
If the player isn't doing any digital processing, 16 bits should be more than suifficient for any home use -- even though it won't be quite 16 bit in practice. IIRC, all other things being equal, people don't tend to hear bit depth reduction until it hits 14 bits (I think the pcabx site has a self-test for this). At home, the ~85-90 dB of dynamic range that '16 bit' CD provides should be more than enough. Most modern pop recordings and remasters don't even begin to take advantage of that range anyway.
There is no talk of dither, noise shaping, etc. What there is are empty claims of 14 bits being good enough. Where is your result of double blind tests that demonstrate that?
What *you* remember or not really doesn't matter.
For a *fact*, highly trained listeners have reported ABX results for comparisons on Hydrogenaudio. What comes immediately to mind are credible reports of hearing difference between 320 CBR mp3 and source, using good codecs. That's credible because people who tune lossy codecs -- and are thus 'trained' to hear subtle artifacts of mp3 encoding -- hang out there.
They also hang out here:
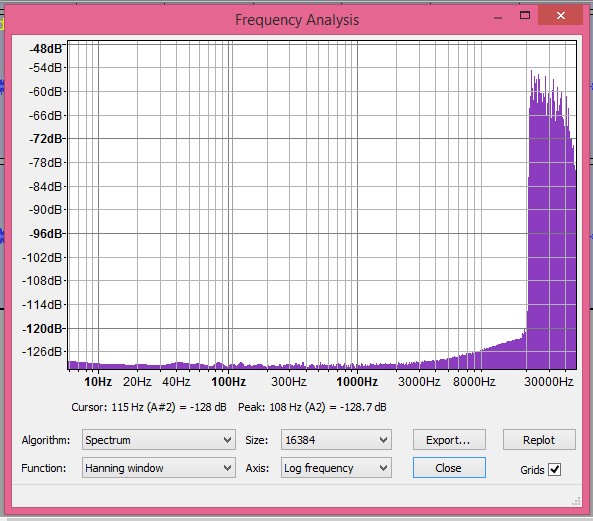
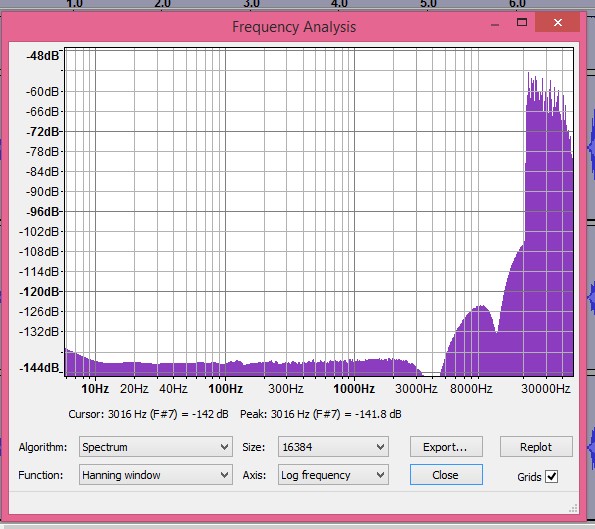
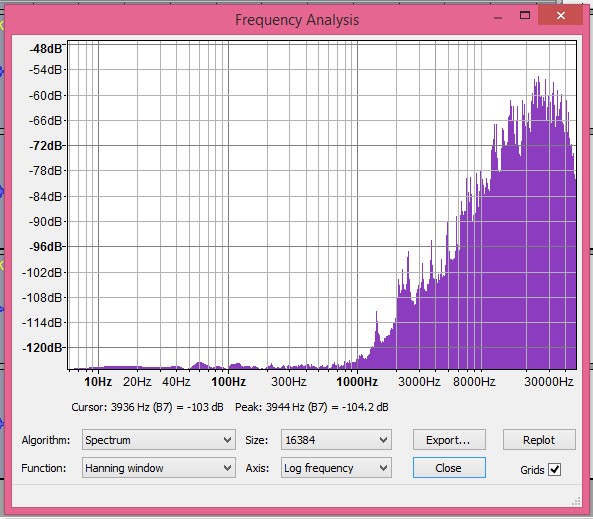
Not quite the topic of the thread but nevertheless part of similar arguments, here is a comparison of Arny's 24/96 file downsampled to 16/44.1 compared to 320 kbps MP3 of the same:
=================
foo_abx 1.3.4 report
foobar2000 v1.3.2
2014/07/19 19:45:33
File A: C:\Users\Amir\Music\Arnys Filter Test\keys jangling 16 44.wav
File B: C:\Users\Amir\Music\Arnys Filter Test\keys jangling 16 44_01.mp3
19:45:33 : Test started.
19:46:21 : 01/01 50.0%
19:46:35 : 02/02 25.0%
19:46:49 : 02/03 50.0% << dog barked in my ear wanting to go out ")
19:47:03 : 03/04 31.3%
19:47:13 : 04/05 18.8%
19:47:27 : 05/06 10.9%
19:47:38 : 06/07 6.3%
19:47:46 : 07/08 3.5%
19:48:01 : 08/09 2.0%
19:48:19 : 09/10 1.1%
19:48:31 : 10/11 0.6%
19:48:45 : 11/12 0.3%
19:48:58 : 12/13 0.2%
19:49:11 : 13/14 0.1%
19:49:28 : 14/15 0.0%
19:49:52 : 15/16 0.0%
19:49:56 : Test finished.
----------
Total: 15/16 (0.0%)
I just selected the beginning of the file and the difference was very clear to my ears.
You challenged me to pass such a test on AVS and I ran and reported the results both there and here.
The *important lesson* here is not that training can increase discriminatory ability -- no one in their right mind disputes that -- it's that reports of difference need to be accompanied by consideration of the *possible sources of that difference*. Saying 'some people have better hearing than others' is only part of the story, and not the most interesting here.
ABX tests do not provide any qualitative differences so you can't ask for "possible sources of difference." Nor anyone taking such tests is required to then explain the results. The listener has no such responsibility. Whoever created the tests needs to go back to the drawing board to find out why their assumption and hypothesis was wrong.
Remember, once I passed this test, people who said it was impossible also started to pass it just the same. We had poisoned the well so much with this talk of impossibility that even the people who could tell the difference, were not trying hard enough. This even included Arny himself. They are all learning to be a critical listener and ignore biased introduced to the test by folks like yourself and Arny.
Tell someone an ABX test is impossible to pass and guess what? Most people will give up immediately if the differences are small. You think double blind tests get rid of bias? Think again. We worry about listener being unbiased but then forget about the deadly sin of the experiment creator not being so.
No one here, you included, I am quite sure, actually hears the >20kHz content of the ' high rez' files. *Possibly* the bitdepth difference is audible, depending on how the conversion was done, and how abnormal the listening was (the fact that two variables -- SR and bit depth -- were changed is one of the issues making these tests problematic). Beyond that, we are left with either artifacts (from conversion, from the software , from the hardware) introduced into the audible band...or phenomena unknown to science-- and extraordinary claim require far more extraordinary evidence that provided thus far.
As I mentioned to Arny, now that these tests can be passed, then analysis can be done. Until now folks had their head in the sand thinking even more dramatic degradations such as 14 bits are inaudible as you claimed. This is why we have such a positive step forward as a result of these tests.