
RUR-Same outcome as flipping a coin?
Thus proving my point about not peforforming a proper statitistical analysis.
RUR-Same outcome as flipping a coin?
Gregg, if I make 10 observations and only six of them are correct, the odds of my continuing the test and ultimately getting a statistically significant % correct are pretty much nil. It's pretty obvious by then that I can't tell the difference.Thus proving my point about not peforforming a proper statitistical analysis.
There's no requirement that the test sample be new and unfamiliar to the subject, Gregg. ITU-R BS.1116-1, which is often cited as a basis for audio DBT's, stipulates that test samples be selected which best show the differences between the pieces of gear under test (I'm paraphrasing). When I did my DAC DBT's, I spent considerable time listening to each DAC and selected musical passages which best showed the differences I thought I heard (sighted). I then conducted the DBT using those passages. In some cases, the differences I thought I heard sighted were not borne out in the DBT. In others, it was.
I agree (in part). That is a significant problem with the testing process. And then given that everyone is an expert on the internet, the process is used as a sword to challenge claims of difference or preference. Most definitely inappropriate and certainly less than cordial.I did not say that that it is required that it be unfamiliar. Only that so often the room, equipment, and source material is fostered on the examinee for the first time.
Not sure what the question was that led to your answer Garybut here is some measurements:
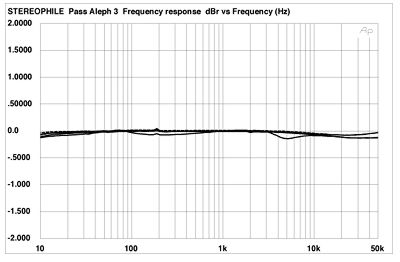
Pass Aleph 3:
Fig.1 shows the Aleph 3's frequency response. It is nearly ideal—even with our simulated real load, the deviation from flat is inconsequential.
And BAT:
Fig.1 Balanced Audio Technology VK-55SE, High output tap, frequency response at 2.83V into: simulated loudspeaker load (gray), 8 ohms (left channel blue, right red), 4 ohms (left cyan, right magenta), 2 ohms (green). (1dB/vertical div.)
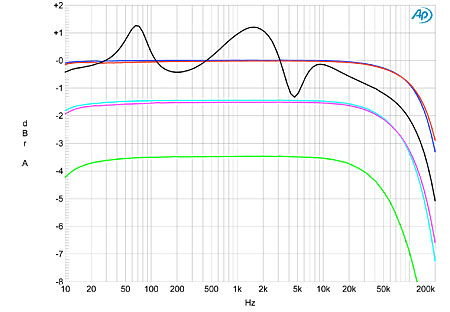
So what do we learn here?
Someone should be fired at stereophile magazine
So let's take the simulated load as that is the common thread. The BAT surely has wild variations in the response.
Now let's read some of the subjective words from the review:
"....the VK-55SE was a tad more tonally rich delivering the chorus than the Atlas or Nu-Vista, and the Atlas had a bit more sparkle than the Nu-Vista and the '55SE. ..."
"...the sound was vivid, relaxed, and liquid. Delmoni's 1780 J.B. Guadagnini violin has an unusually big sound, and the '55SE reproduced that bigitude, and the Guadagnini's timbral impact, with clarity—it didn't sound too big or too bright, but just right...."
Let me ask you this: which one of these two evaluations is more reliable? If I measured the unit again, would it produce wildly different results?
What if I had someone else review the BAT? Would they use the same words or even similar ones? What if I took the markings off the BAT and put in the box with the name Mark Levinson on it making it look like a solid state amp? Would the above words change in the review then? What if it said Carver or Sony on it? What if I said it cost $500 for the amp or $50,000? Would the words change?
Above all, how are the above words any different than any other high-end amp review? And what do the words really mean anyway? Sparkle means what? More highs? What does "ease" mean?
So again, without judging the execution, how would you rate the reliability of each evaluation type?
(...) Let me ask you this: which one of these two evaluations is more reliable? If I measured the unit again, would it produce wildly different results? (...)
I didn't point out that the measurements were incompetent. What was incompetent was lack of standards at the magazine so that casual observers would not be confused by the sharp drop off in one curve that goes to 200 Khz vs one that only goes to 50 Khz.Measurements as you point out can be incompetenlty conducted and interpreted as you point out. I'll say it again for the last time. You can't destroy the rule by citing a corrupt example.
Pick any definition you like and then tell me the consistency of evaluation using the three methods. I am trying to get us at the Forrest level not the treesOnce again, we have a language problem. What are you evaluating? The sound of the amplifier? Or its capacity to produce beautiful graphs? Or do you just want consistency of the opinion?
Evaluation per se does not mean anything.
.(...)
but my main point is:
But, those who ingore measurements in no way are looking for fidelity to the source, as are those who say it sounds better or right to them. The only way to measure fidelity to the source is with measurements. And, only a few folks on this forum tend to adhere strictly to the rule that they want their gear to be accurate to the source.
(..)
Tom
, here is another. Every system has one more weaknesses. How do you know the material you are using brings those out? Surely a few tracks is not representative of all music ever created.Not sure what the question was that led to your answer Gary
I agree that those terms are hopelessly fuzzy. As are the terms that I mentioned in the post above. However, I personally don't think that THD, IMD and FR tells me the whole picture.
I can see in FR a tonally "warm" amplifier with slightly elevated 80Hz to 160Hz response. I can also listen to an amplifier that I think sounds "warm" but has a perfectly flat frequency response. Where I'm struggling is - is there a way to measure this besides what we already know?
Do you have an example of a "warm" component with a flat FR and distortion and noise low enough to be of little concern?
Tim
Don't look but I am doing that to youAmir I wish I could cross examine you.
You are no different than Tim and I in that respect. We use our audio equipment to listen to music and not mow the lawnThe reason we put more emphasis on listening is because that is our role in this puzzle. We are listeners.
. The difference is that we use sum total of all evaluation tools we have. In your corner, you are dismissing two out of three even though I can show you, heck prove to you in a court of law , that they are incredibly useful and powerful to help us what is best.So Ethan, you buy all of your audio gear based on measurements and without listening to it/them before you plunk down your cash?
Measurements can be predictors of sound quality but that's it.
Sometimes I forget that you are listening through a $150 Pioneer receiver and I need to keep that in mind in order to put your comments in perspective.
I'm not bothered by wow, flutter, crosstalk, or inner groove distortion because I don't hear any of those distortions raising their ugly heads in my system.
Michael Fremer-THE HUMAN EAR IS FAR SUPERIOR TO ANY MEASUREMENT DEVICE IN DETERMINING THE TOTALITY OF WHAT'S HEARD.
Gary,
I wrote it some months ago in another thread. Happy you like poisons!
Subtractive and Additive?
Most of the best hifi components are not completely neutral in the sense they do not change the signal - if they were neutral they would sound all the same, and I have never had two different preamplifiers that sound the same. Some of them manipulate the signal in a way it helps us recreate our image of music.
Do you thing that great designers add something to the signal that enhances the music or they simply remove nasty information that masks our perception of some information existing in the recorded music?
| Steve Williams Site Founder | Site Owner | Administrator | Ron Resnick Site Co-Owner | Administrator | Julian (The Fixer) Website Build | Marketing Managersing |